
AI-Enabled Teams #2: Clarifying Our AI Stance
Creating constraints with shared direction and a paved road

Welcome to the latest issue of my newsletter series, ‘AI-Enabled Teams’, where I’ll cover the journey of AI adoption inside an engineering team. The full context of this series can be found in the introduction post.
Our AI half-hype-driven team is now at the beginning of our adoption, or rather, formalising our adoption. When I was asked to get this initiative going, I knew clarifying our AI stance should be our first step. This step was inspired by the DORA AI Capability Model, which is called “Clear and communicated AI stance,” which is pretty well described by the name.
Having a clear stance helps reduce the ambiguity that our team members might have. Are we going to lose our jobs? Are we going to get replaced by machines? Would our current skills be irrelevant? It’s hard to tell if anyone in our remote-first team is anxious around these topics. However, it’s not hard to imagine people having such a prediction and developing their own fears.
We begin our journey through a 30-minute workshop.
Where are we heading?
We kicked off the workshop by having our Head of Product Engineering act as a sponsor to endorse our AI adoption initiative. Our sponsor mentioned that AI is here to stay, and let’s not fall behind. The goal that we set by this point is a directional one, and we did not declare where the finish line is, by intention.
As much as I dislike any top-to-bottom approach, a power dynamic exists in any organisation, and we have to attack this adoption from all possible angles. This three-minute endorsement served as an enabling constraint, as it gave an explicit permission for the team to adopt AI. We made it firm that we, as a company, will go through this together and learn new skills around AI if we have to, tightening our stance on AI.
Where are we?
While setting a goal could be aspirational, as a student of complexity, I thought it’s more important for us to understand where we are as an organisation. We are unlikely to get to where we want to be if we don’t recognise our current dispositional state. To surface signals about our current dispositions, I created three Likert-scale statements using a screenshot from the recent DORA report:
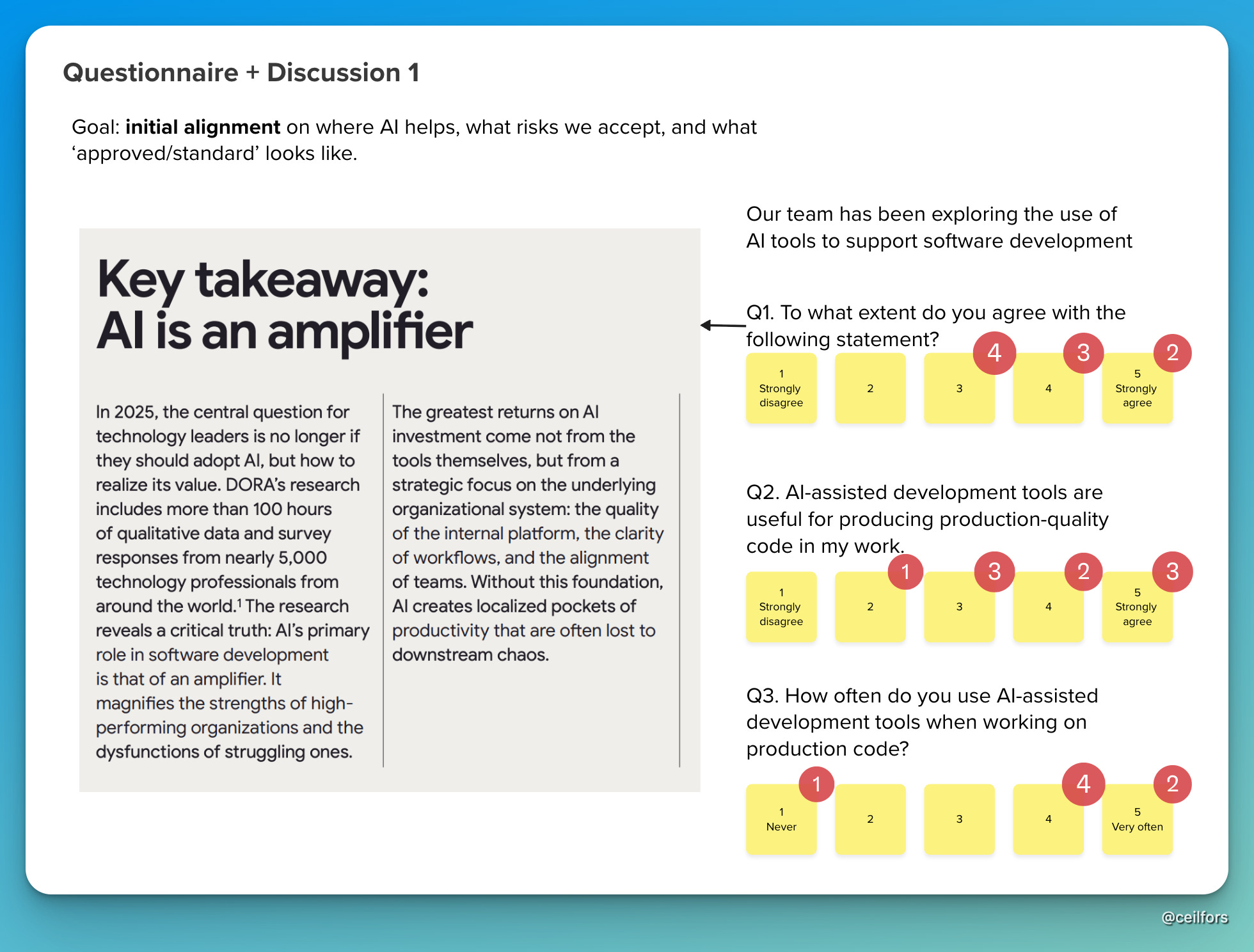
As you can see from the result, thankfully, we have quite a good starting position as an organisation. We did not have strong disagreements around the statements presented.
I recall having a conversation with our sponsor where he suggested us having a strong transformation and training programme. Having encountered charlatan coaches in the past gave me a hard knee-jerk reaction. I promised him that we’re not as bad as he thinks we are, and this survey should reassure him.
How do we move forward?
It’s clear now that we’ll adopt AI, but some question marks remain. How do we adopt it safely?
There were worries about our use of multiple AI vendors and the impact of this practice on the business. A couple of us have been experimenting with various AI agent tools with the belief that it’s best to let engineers use the tools they like. We’re scrappy, and we disliked the idea of company-approved tools. These vendors are releasing new models every minute. We should always use the best one, should we not? There was an argument for consolidation for cost reduction (which I thought was a weak argument).
With this context in mind, I revealed the next set of Likert-scale statements in the workshop. To make the workshop more productive, I prepared the questions to be more concrete, articulating the worst and best outcomes of consolidation, expecting to spur some debate. I thought this was more productive than asking a generic, should we consolidate question.
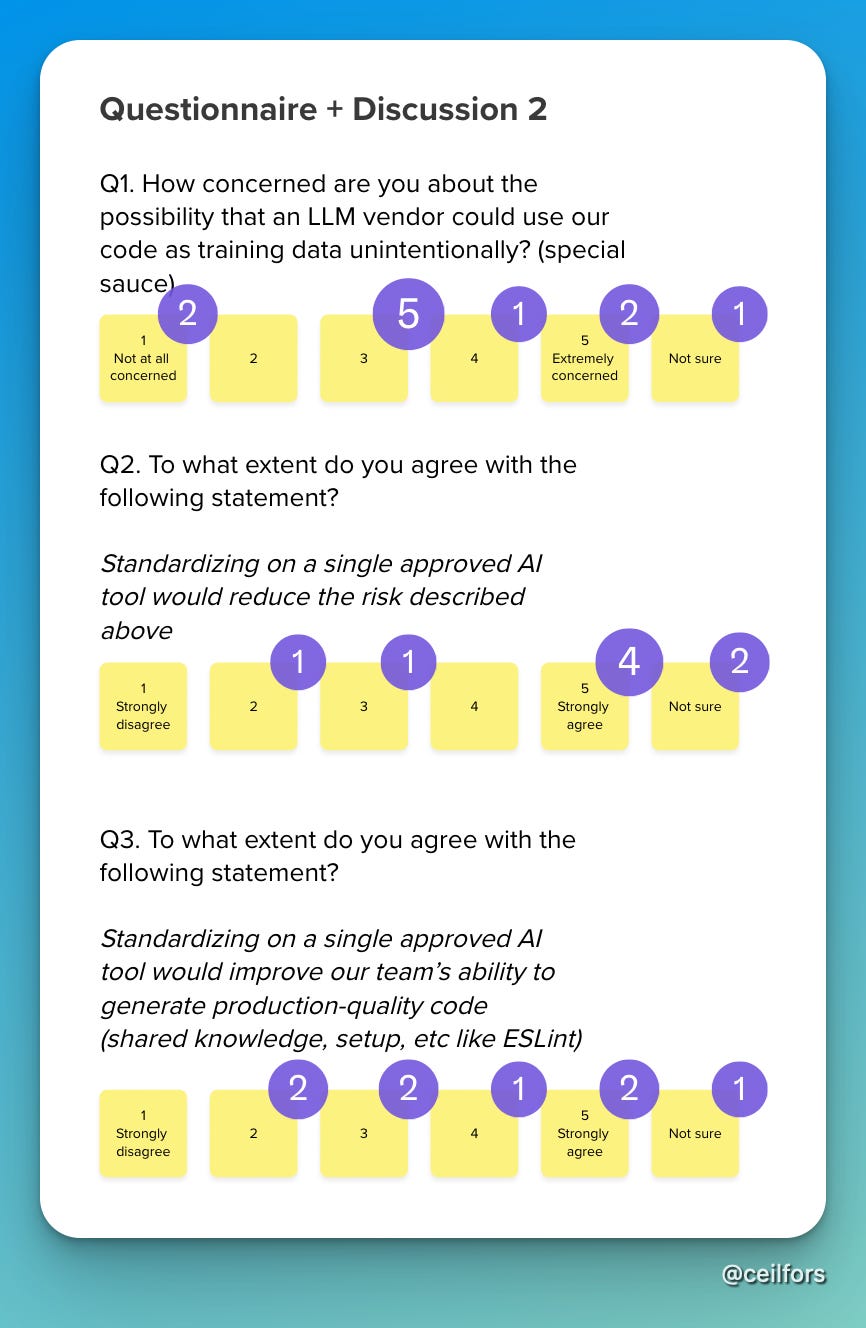
One of the most important outcomes of the debate was that our business does not have any special secret, patented source. We, as a business, are not too concerned about the use of LLM against our codebase.
We also discovered a new tension, which was revealed by the third Likert statement. Some of us still like model hopping and are attached to our tools. We did not resolve this tension in the workshop as we ran out of time. The good news was that I did not see strong disagreements.
Concluding the tension
Seven days after the workshop, after thinking and researching, I’ve decided to make a Request for Comments to resolve the tension.
Below is the original RFC I’d written for the team:
We’re going to invest more in Claude Code as our coding agent (full Anthropic stack, agent, and LLM), so we can adopt it well as a team.
What matters most: Brand trust and adoptability, Agent and model compatibility, One tool to share
1. Brand trust and adoptability
This one is subjective, but I personally trust the Anthropic brand more than OpenAI. They’ve positioned themselves around safety since day 1. I’m also cautious about any company whose business model is strongly tied to advertising. More importantly, regardless of vendor, I want us to be confident about clear enterprise/API data guarantees—especially around retention and whether our data is used for training. As we onboard more engineers, we’ll naturally have more opinions. In the industry, there are also strong feelings about leadership (Sam Altman) and company reputations, and that can affect adoption for tools we standardize on.
2. Agent and model compatibility
We learned today that context is king for influencing an LLM’s response. (Editor note: We had just finished a LLM learning hour when I posted this RFC.) Picking an agent that’s designed around the model should produce better results. Different models respond better to different conventions (e.g., structured tags vs. plain text), and they behave differently under the hood. Claude Code, for example, can inject system reminders into the context window, like:
<system-reminder>
Note: [FILENAME] was modified, either by the user or by a linter. This change was intentional, so make sure to take it into account as youThis is a similar trade-off to adopting hybrid cloud vs. going all-in on a single cloud provider: tighter integration can be a big advantage, but it comes with more coupling.
3. One tool to share
All of these tools inevitably have different configs and different ways to make usage safer. The community is usually behind on sharing consistent standards (think “skills” protocols, reusable workflows, etc.). It’s also easier to share concrete knowledge when we’re all using the same default tool, rather than translating ideas across multiple setups. I know many of us are trying different models. In my head we’re hitting Fredkin’s Paradox:
The more equally attractive two alternatives seem, the harder it can be to choose between them—no matter that, to the same degree, the choice can only matter less.
My hypothesis is we’ll get way more benefit by using one vendor really, really well as a team. I’m not saying we’re banning Cursor or other tools right now. You’re still free to explore. I’m saying: we’ll pave the default path toward Claude Code and its surrounding tooling so the team can align and compound improvements.
I had good feedback from the RFC. Our sponsor, who had a strong desire to consolidate, approved it, which is great news.
The idea of forced consolidation was one of the biggest worries I had. A paved road would form a permeable constraint, not a rigid one. In a complex system such as ours, a rigid constraint might not be the best one, as it may create shadow IT and resistance.
We also had an engineer who was worried about our Cursor subscription being stopped, to which I responded, that’s not what’s happening.
In making this decision, I mostly thought about our junior members whose progress might stifle with the idea of multi-tool-multi-model chaos. I know that the cool kids have moved on to gastown and codex, and I have a burning desire to try them out, too, but it wouldn’t have been the right call. We have to get everyone on the journey together.
If we get this right, this decision should kick off a flywheel of deeper learning in the teams, sharing tips or tricks for Claude Code, rather than sharing hypes.
Closing: This concludes our first step of clarifying our AI stance, turning the adoption from a set of hype-driven experimentation into the start of building an organisational capability.