
Building AI-Native Teams #3: From Black Box to Boxes-And-Arrows
A learning hour to help engineers build intuition for LLMs, chatbots, and agents

Welcome to the latest issue of my newsletter series, ‘AI-Enabled Teams’, where I’ll cover the journey of AI adoption inside an engineering team. The full context of this series can be found in the introduction post.
Frustration is a common reaction among engineers new to AI. Why is AI not telling me the truth? Why did AI lead me down the wrong path? Engineers need to build a good intuition about AI for successful adoption, and we could achieve a better intuition by unpacking the magical black box of AI.
Building this intuition is important as the non-deterministic nature of AI often makes engineers operate, in Cynefin terms, in a Complex domain, where the cause and effect relationship is only partly visible. With better intuition, we understand better what we can and can not do against AI. A better intuition makes part of the work sit in the Complicated domain, where teams could analyse patterns and make improvements to their approach to AI.
A better intuition of how to use a technology effectively can be done by peeling the technology’s abstraction one level deeper. When my daughter got frustrated because the TV remote did not put the volume up, we went one abstraction level deeper. Understanding that the remote control blasts infrared light that needs to be received by the TV, built her intuition. She needs to point the remote at the TV's infrared receiver.
A similar idea can be applied to understanding AI chatbots and agents, too. Just like the TV remote control, we don’t have to go too deep into what infrared is. Even though the topics of attention and transformers are interesting, you don’t have to go that deep to build the initial intuition.
What follows is a blend of the learning hour I’ve designed, my thought process, and the result of the learning hour (Hat tip to Pete Hodgson, who has greatly influenced the content of the workshop.)
LLM inputs and outputs
We kick-start the learning hour by focusing on LLM. Simple boxes and arrows are engineers’ favourite tools to understand abstractions. Let’s use that. I deliberately exclude coding agents or AI chatbots from this initial picture.
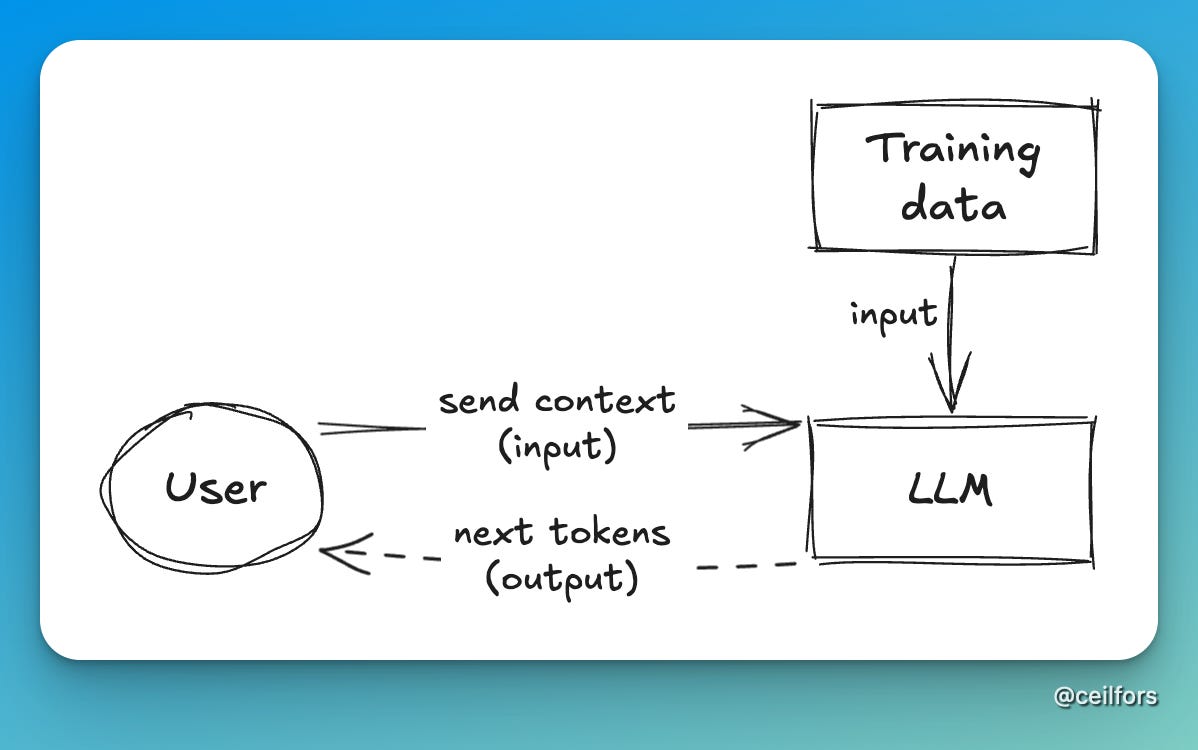
This idea is an oversimplification at best, but one thing I emphasise over and over again throughout the learning hour is the idea that there are only two inputs to LLM to produce output (next tokens). Arguably, the training data could be framed as a database, but it doesn’t really matter at this point. I thought this oversimplification was necessary to build the foundational understanding of LLM.
Like any technology, we learn best when we can play around with it and observe the input and output in real time. This has proven to be difficult, as many AI tools out there have built a thick harness around LLM. Luckily, I found this fully hosted GPT-2 app that I could use for the demo. I got an ooh and an aah at this point. Something clicked in people’s heads.

“But AI chatbots don’t seem to respond to me with next tokens”
We understand now that a language model's job is to produce the next tokens. However, it does not explain how AI chatbots work. Clearly, these chat assistants are responding to us conversationally. They’re not completing our sentences like what’s been demonstrated so far.
Think about it for a second. Imagine that you’re sending a prompt to an AI chatbot, “What’s the capital of”, the chatbot wouldn’t complete your sentence. It might even ask a question back to you instead and make an attempt to have a conversation.
Here, I asked the team to spend 5 minutes hypothesising how an AI chatbot might work, hoping for them to build a stronger learning connection. Unfortunately, I didn’t get any good answers as my questions were poorly written.
The magic here lies in some invincible texts that got injected into the input sent to the LLM by the chatbot. Our user prompts are modified by the chatbot to influence the response returned by LLM.
I used the same hosted LLM to demonstrate this.
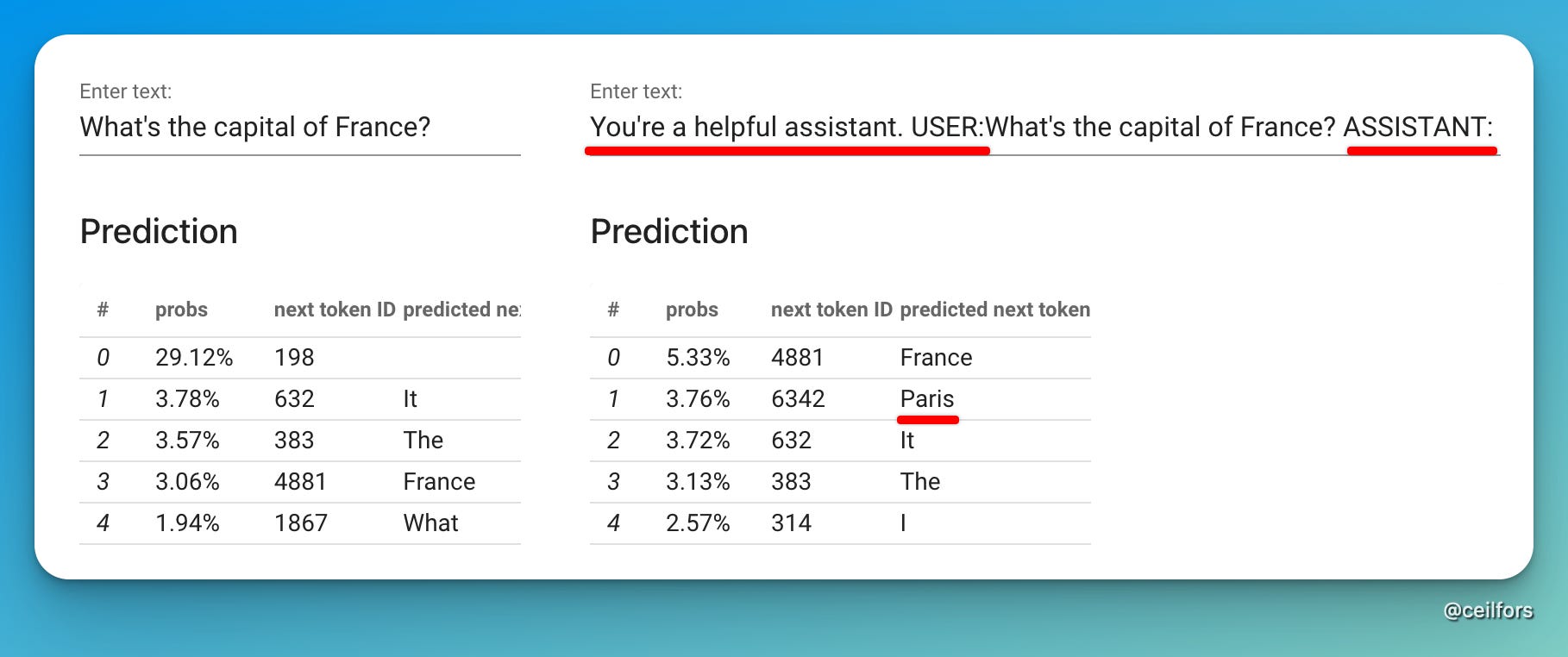
Notice how, in this LLM, getting the LLM to role-play produces better prediction. (Do note that in reality, role-playing is only one trick the harness does. There’s much more to it.)
So, back to the original question, why is an AI chatbot not telling me the truth? Why is it hallucinating? In this LLM example, even with the role-playing trick, it would have told me that the capital of France is France!
By this point, hopefully, the team would have built enough intuition to answer this question. And the next time they send their prompt, they could visualise what’s going on behind the scenes.

What about agents?
Given that the team has been hyped-driven, uses a plethora of coding agents already, I thought it was worth unpeeling the abstraction further for agents. We started by reading the definition of agents by Anthropic’s Hannah Moran:
Agents are models using tools in a loop
All engineers would understand what a loop is, but what is a tool? How does the agent decide on what tool to call? Here again, we’re a bit stuck. Just like AI chatbots, the harnesses were quite thick, so activities are happening behind the scenes that we couldn’t really observe.
Thanks to Pete Hodgson, I discovered that I could observe the tool call in detail in Claude Workbench.
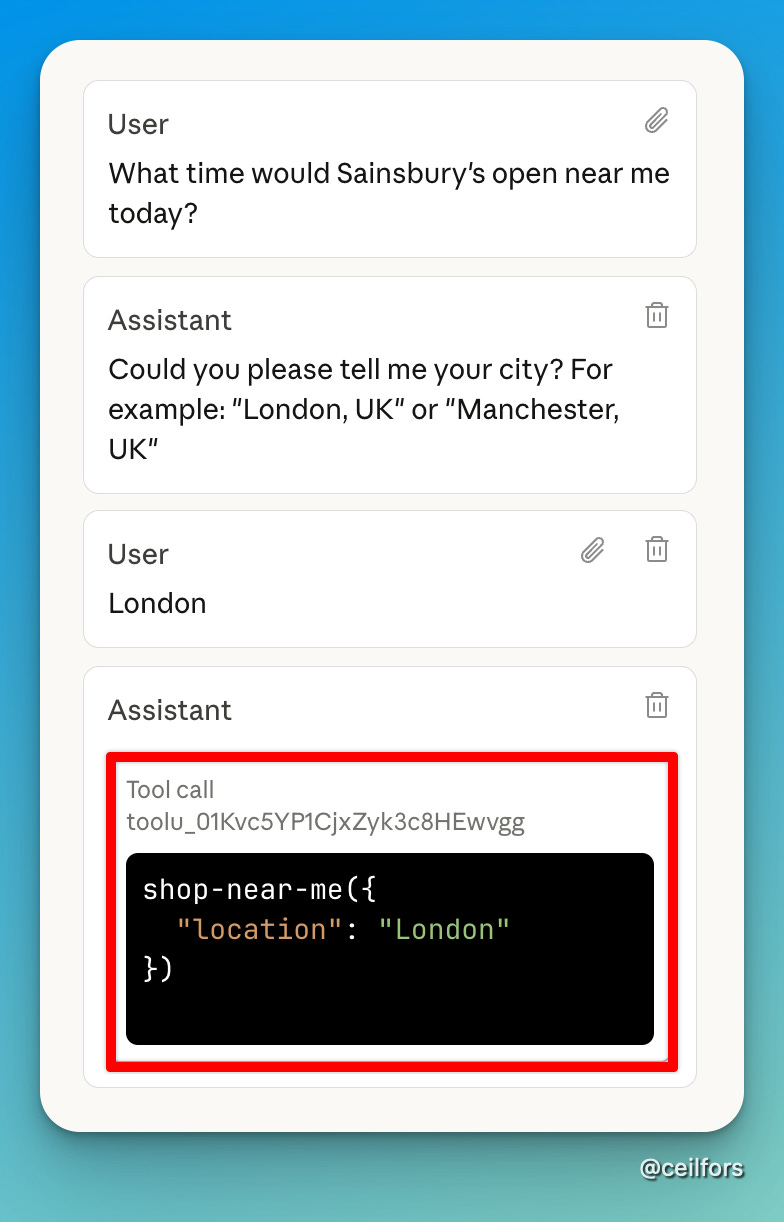
And before we close, I reiterated the idea that the only LLM input we could control is the context, and the reason LLM understands this specific tool is that the detail has been injected into the context window.
This is the final boxes-and-arrows diagram.
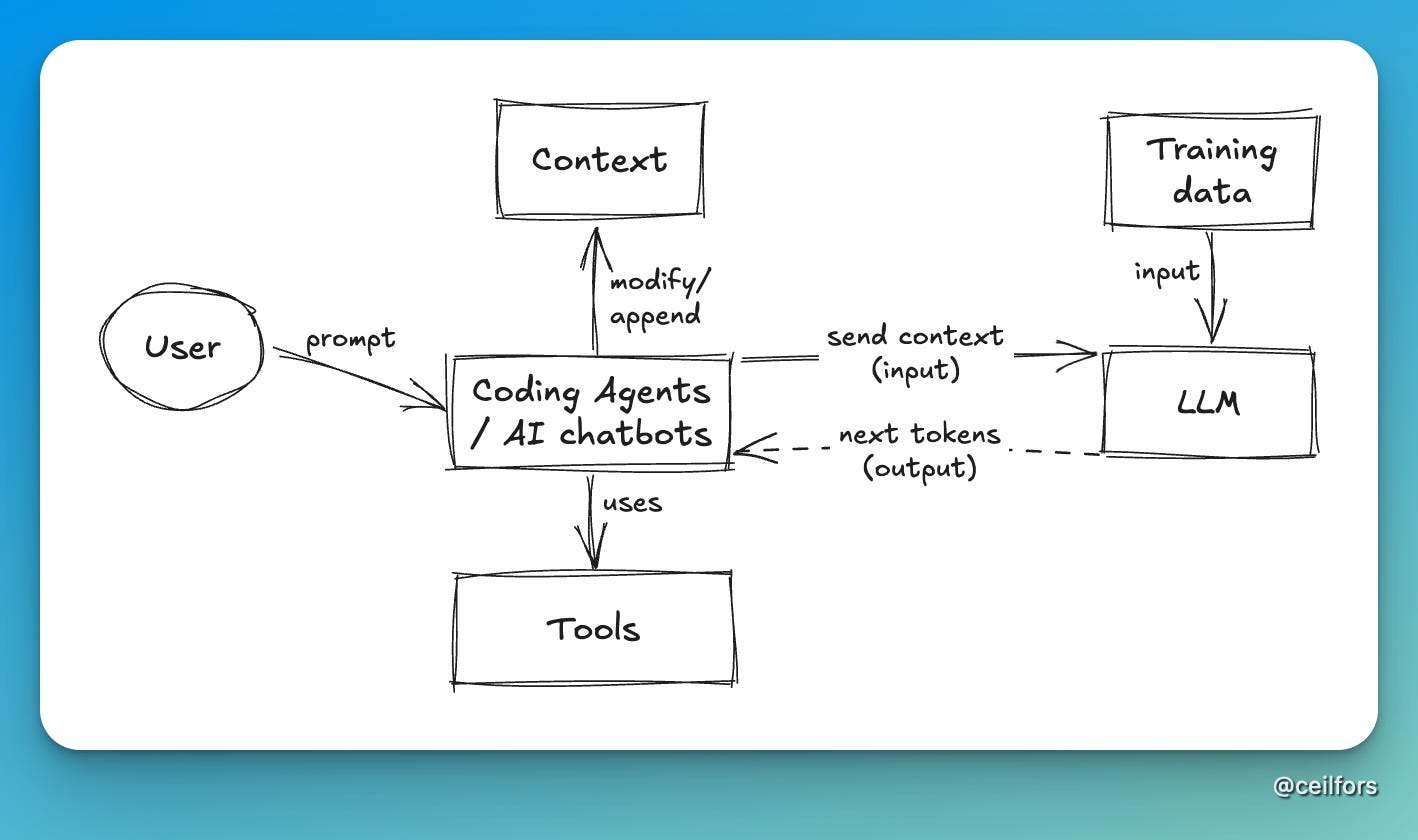
Closing
We first closed this learning hour with a quiz, as I felt that the activities were fairly theoretical. I’m pretty pleased with the results.

And with the quiz answered, we closed it with reflective questions. The answers made me pretty confident that we’re making good progress in this AI adoption journey.

Speaking of good progress, next up, I’ll write about what I’ve decided to measure. Stay tuned.